在 Redis 中, 为了支持高可用, 官方提供了 3 种方式
- 主从复制
- 哨兵模式
- 集群模式 (Cluster)
但是主从复制和哨兵模式都有一个问题: 无法水平扩缩容, 而这个问题在集群模式中得到了解决。
假设有 3 个 Redis 节点, 所有的数据均匀的分散在 3 个节点中。
如果现在需要往里面加入一个新的节点或移出一个已有的节点, 那么就需要对已有的数据做迁移。
这个迁移可以说是涉及到所有数据, 这是一个大成本的操作。
Redis 为了避免全数据量的迁移, 在集群中引入了一个槽的概念。
在 Redis 的集群模式 (Cluster) 中, Redis 内置了 16384 个哈希槽, 将以前数据存储在 Redis 节点的转为数据层存储在哈希槽 (实际最终还是在具体的节点中)。
当我们向 Redis 中存入一个 key-value, 会先通过 crc16 算法对 key 计算出一个值, 再通过这个值对 16384 取余数, 得到其存储到哪个哈希槽中。
这里面有个问题: 为什么引入槽设计后, 可以避免全量的数据迁移, 同时还有其他什么好处吗, 下面简单的做一个分析。
1 数据分区
Redis 集群如果需要支持水平的扩缩容, 就需要先解决一个问题: 数据分区, 即如何将大型数据集按一定的规则或策略进行分割或划分, 以便更有效地管理、存储和处理数据。
常见的数据分区有
顺序分区
范围分区
哈希分区
…
其中哈希分区由于其天然的随机性, 使用广泛。集群的分区方案便是哈希分区的一种。
哈希分区的基本思路是: 对数据的特征值 (如 Key) 进行哈希, 然后根据哈希值决定数据落在哪个节点。
常见的哈希分区包括: 哈希取余分区, 一致性哈希分区, 带虚拟节点的一致性哈希分区等。
衡量数据分区方法好坏的标准有很多, 其中比较重要的两个因素是 数据分布是否均匀, 增加或删减节点对数据分布的影响。
由于哈希的随机性, 哈希分区基本可以保证数据分布均匀。 因此在比较哈希分区方案时, 重点要看增减节点对数据分布的影响。
2 哈希取余分区
哈希取余分区, 对特征值进行哈希, 得到一个需要的哈希值, 然后通过这个哈希值取余已有的分区数, 得到另外一个值, 这个值就是当前数据后续所在的分区位置。
比如当前 Redis 集群中有 3 个节点, 往这个集群中存入一个 key-value, 假设对 key 哈希后得到的值为 15, 15 % 3 = 0, 那么 key-value 这对键值对就存在 0 号节点。
该方案最大的问题是: 当新增或删减节点时, 节点数量发生变化, 系统中几乎所有的数据都需要重新计算映射关系, 引发大规模数据迁移。
比如当前有 3 个节点, 其中 (假设 hash 函数为 hash(数字) = 数字)
节点 A 已有数据 (0, 3, 6, 9)
节点 B 已有数据 (1, 4, 7, 10, 13)
节点 C 已有数据 (2, 5, 8, 11)
现在向里面加入多一个节点, 变成了 4 个节点, 原本 hash(3) = 3 % 3 (个节点)= 0, 变为 hash(3) = 3 % 4 = 3。
因为多加了一个节点, 计算后 3 由原本的 A 节点变为了 D 节点, 所以需要将 3 从 A 迁移到 D 节点, 最终整个集群数据变为
节点 A (0, 4, 8)
节点 B (1, 5, 9, 13)
节点 C (2, 6, 10)
节点 D (3, 7, 11)
可以看到集群中的数据变动还是挺大的, 如果这个发生在 Redis 那种几百 G 的数据中, 需要迁移多久。
3 一致性哈希分区
为了解决哈希取余分区, 节点的变更, 带来大数据量迁移的问题, 就有了一致性哈希分区。
一致性哈希分区原理
- 设定有 0 - 2^32-1 个整数, 将这些整数按照一个圆环的形式排列起来, 然后 0 和 2^32-1 相连, 这样就形成一个哈希环
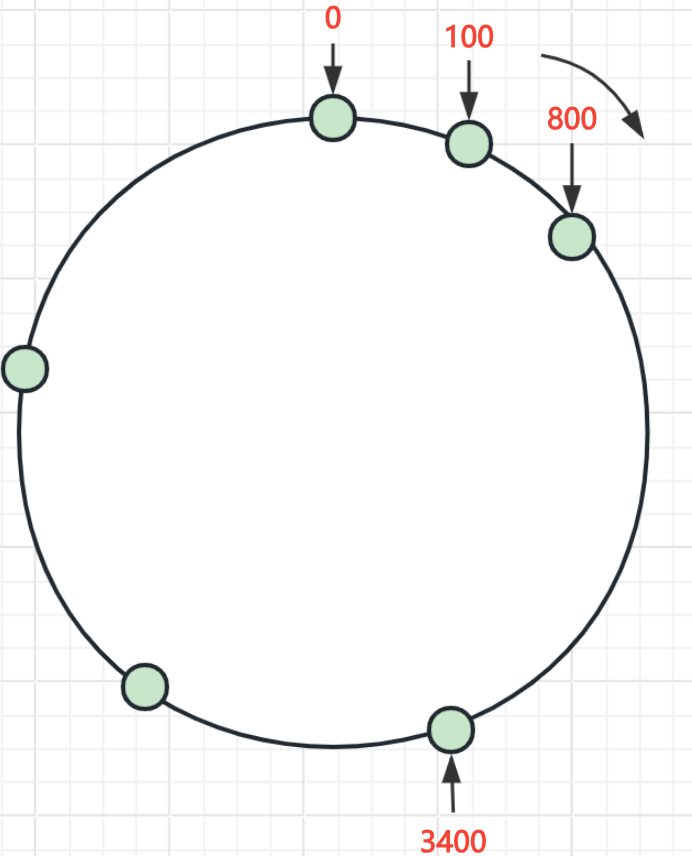
- 将已有的几个 Redis 节点通过计算得到一个在 0 - 2^32-1 中的某个值, 这个值就是当前节点在哈希环上的位置
- 当有数据需要存储时, 先计算数据的哈希值, 得到一个在 0 - 2^32-1 中的某个值, 也就是在哈希环上某个位置
3.1 如果这个位置有节点, 则这个位置就是数据的存储的节点
3.2 如果这个位置没有节点, 则在哈希环上的这个位置开始, 顺时针的方向向前找到第一个节点, 将数据存储到这个节点中

与哈希取余分区相比, 一致性哈希分区将增减节点的影响限制在下一个节点。
- 当新增一个节点时(设前一个节点到新增节点的区间为 A, 设新增节点到后一个节点区间为 B), 那么只需要将区间 A 的数据从后一个节点迁移到新增节点中即可
如图: 新增一个节点 node-4, 此时只需要将数据 data 从原本的 node-1 迁移到 node-4 中即可

- 当减少一个节点时, 只需要将这个节点的数据存储到其顺时针方向的下一个节点即可
如图: 新增一个节点 node-1, 此时只需要将数据 data 从原本的 node-1 迁移到 node-2 中即可
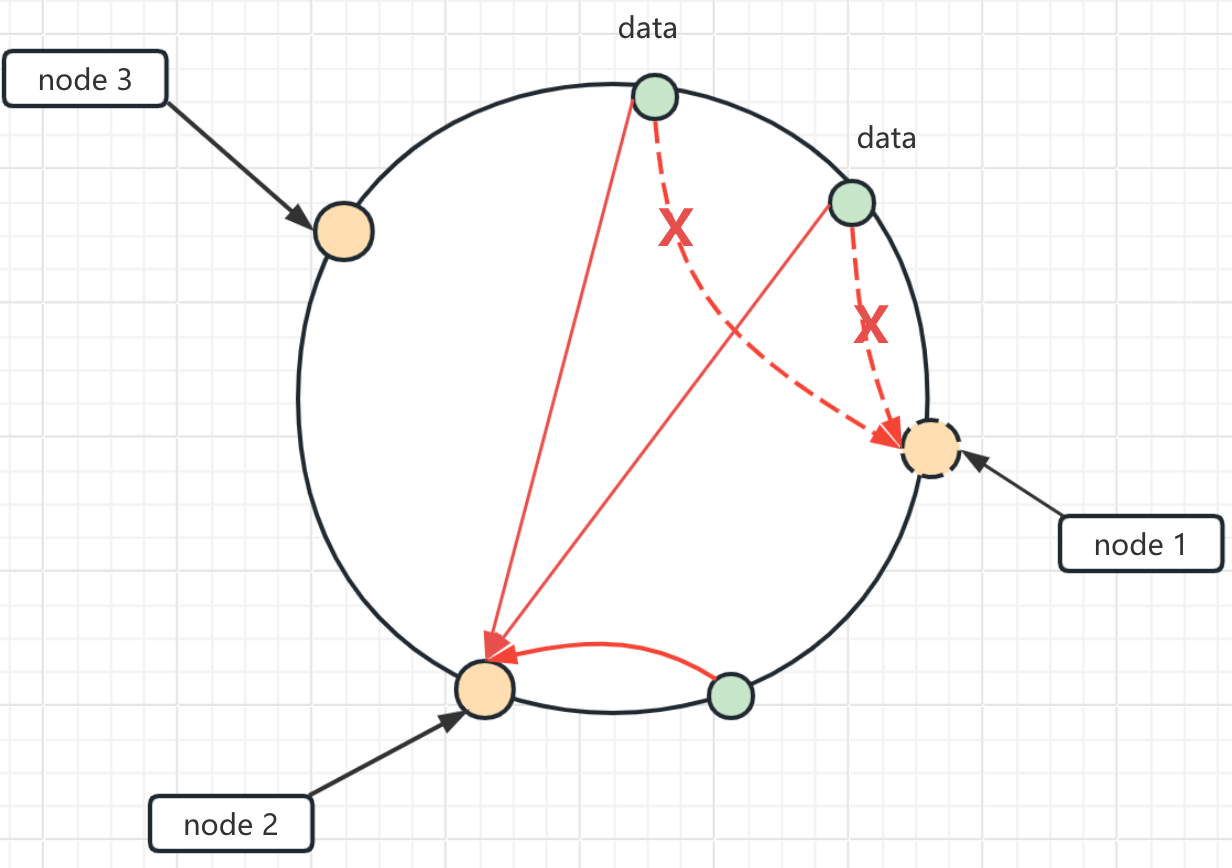
如图中, 在一致哈希算法中,如果增加或者移除一个节点,仅影响该节点的下一个节点。
但是一致性哈希算法不能保证节点能够在哈希环上分布均匀,这样就会带来一个问题: 数据倾斜, 可能存在某些节点的数据比其他节点多/少的情况。
如果某个节点的数据量过大, 会导致这个节点的负载过高, 从而影响整个集群的性能, 如果这个节点挂掉, 会导致整个集群的大量的数据无法访问等问题。
4 带虚拟节点的一致性哈希分区
一致性哈希分区的问题在于节点不能在哈希环上分布均匀, 但是如果有大量的节点, 节点的分布就会更加均匀, 极端点, 环上的每个位置都有一个节点, 这样就可以保证节点的分布均匀。
但是实际中, 节点的数量是有限的, 为了解决这个问题, 引入了虚拟节点的概念, Redis 集群使用的便是该方案, 其中的虚拟节点称为槽 (slot)。
具体做法是,不再将真实节点映射到哈希环上, 而是将虚拟节点映射到哈希环上, 并将虚拟节点映射到实际节点, 形成 2 层的映射关系。
即数据的映射关系由数据 hash -> 实际节点, 变成了数据 hash -> 槽 -> 实际节点。
假设现在有 3 个节点, 有 9 个虚拟节点, 那么每个节点就包含 3 个虚拟节点
- 节点 A 保存 0-2 槽
- 节点 B 保存 3-5 槽
- 节点 C 保存 6-8 槽
那么原本的哈希环, 就变成了这样,
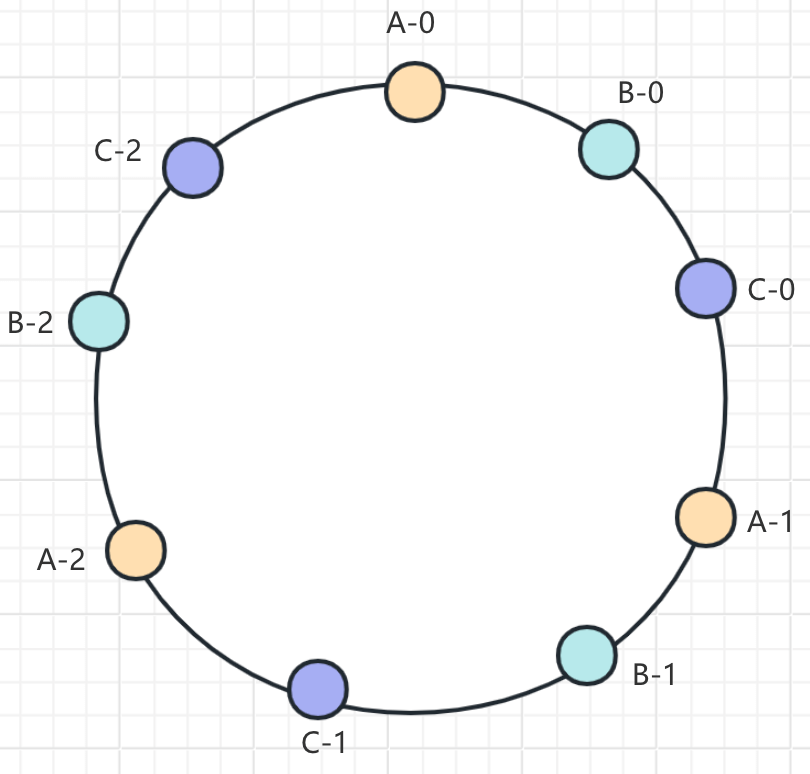
可以看出: 虚拟节点越多,哈希环上的节点就越多,数据分布就越均匀,从而避免了数据倾斜的问题, (现实中, 虚拟节点会很多, 比如 Redis 就设置了 16384 个槽)。
另外, 虚拟节点除了提高节点的平衡, 还可以提高系统的稳定性, 比如: 当有节点数量变化时, 可能有不同的节点分担系统的变化, 提高了稳定性。
比如有一个哈希环, 上面的虚拟节点如下: A-1, B-1, C-1, A-2, C-2, B-2, A-3, C-3, B-3。
现在因为 A 节点挂掉, 那么 A-1, A-2, A-3 的数据就需要迁移到下一个节点中, A-1 ==> B-1, A-2 ==> C-2, A-3 ==> C-3。
迁移的压力就分担到的 B, C 节点, 而不是由某个节点进行处理。
同时, 因为有虚拟节点的存在, 还可以动态地调整每个节点分担的虚拟节点的数量, 比如: 高性能的机器可以分配更多的虚拟节点, 从而提高性能。
可以看出带虚拟节点的一致性哈希分区
- 保证了节点的数据分布均匀
- 提高了系统的稳定性
- 提高了系统的灵活性
因为这些优点, Redis 集群采用了带虚拟节点的一致性哈希分区的方案。
5 参考
9.4 什么是一致性哈希?